머신러닝 중에 Kernel Density Estimation (KDE) 에 대해 설명하고자 한다.
간단히 말하면 KDE는 데이터를 바탕으로 하는 밀도 추정으로 데이터마다 커널을 생성한 히스토그램이다.
밀도 추정에 대한 내용은 아래 블로그에서 자세히 설명되어 있어 생략한다.
http://darkpgmr.tistory.com/147
KDE 란, 아래와 같이 데이터가 존재할 때에

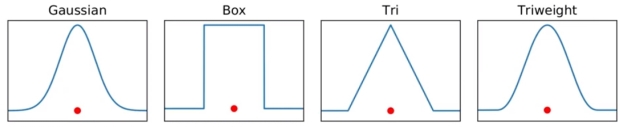
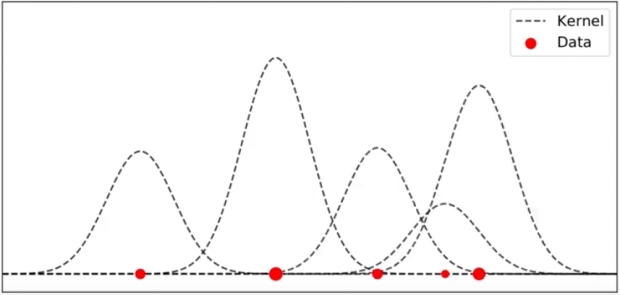
각 데이터에 Kernel 함수를 그린다. (예시는 Gaussian)
– Kernel 의 조건
- K(x) >= 0 : 모든 x 에 대해 양수 값을 가진다.
- K(x) = K(-x) : 모든 x에 대해 대칭된 그래프이다.
- K'(x) <= 0 for every x >0 : 모든 양수 x에 대해 감소하는 그래프이다.
– Kernel 종류
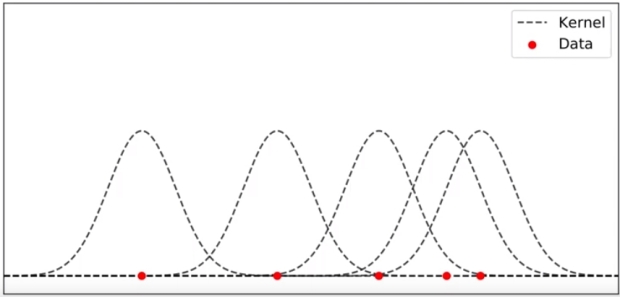
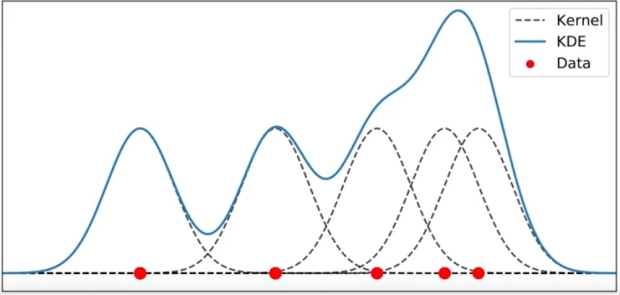
모든 커널 함수를 더하게 되면 다음과 같이 KDE 함수가 생성된다. Kernel 이 겹치는 구간 (데이터가 밀집된 구간) 에는 KDE 함수의 크기가 커지게 된다.
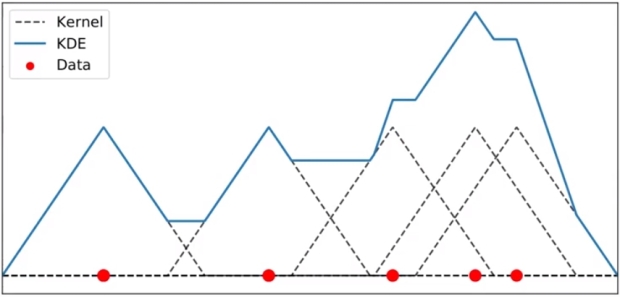
어떤 Kernel 을 사용했는냐는 중요한 문제는 아니다. 단순히 데이터를 표현하는 방법일 뿐이다. Triangular kernel 을 사용하면 아래와 같은 KDE가 그려지나 이는 실제 데이터의 분포(밀도)를 확인하는 데에 지장이 있지 않다.
중요한 것은 Bandwidth 이다. bandwidth 에 따라 그래프의 모양이 달라지게 되고, 적절한 값의 bandwidth 를 적용해야 한다. bandwidth 가 너무 작으면 데이터 의 급격한 변화가 나타나게 되고 너무 크면 너무 smooth 한 그래프가 되어 데이터의 변화를 반영하기 어려워진다.
수식에서 h가 bandwidth 이다. histogram 의 bins 과는 반대 개념.
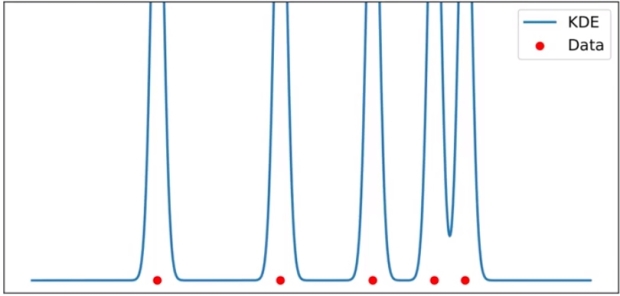
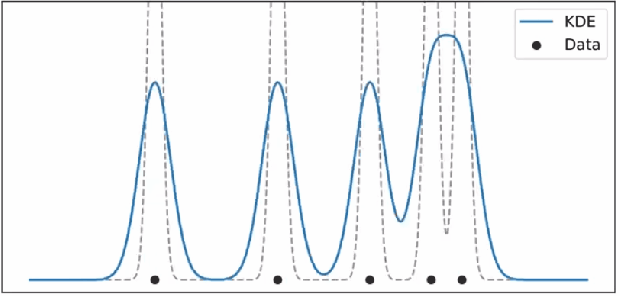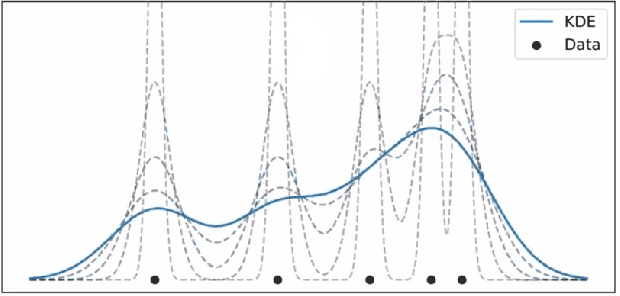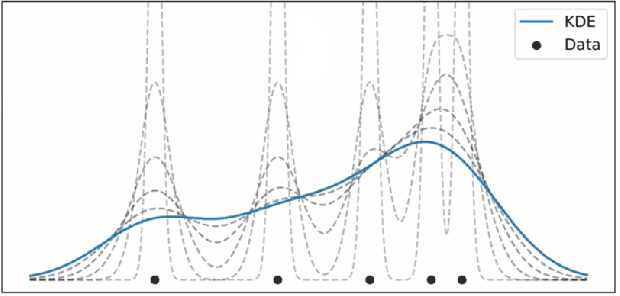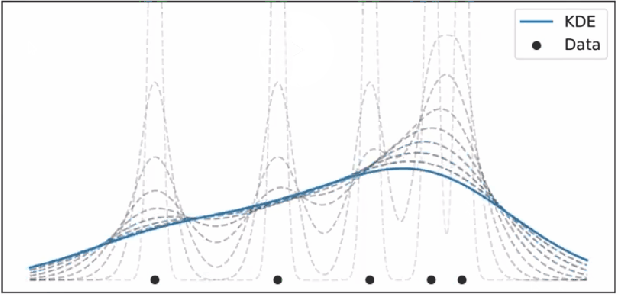

데이터의 분포나 정도에 따라 적절한 bandwidth 를 그래프를 적용해야 한다.
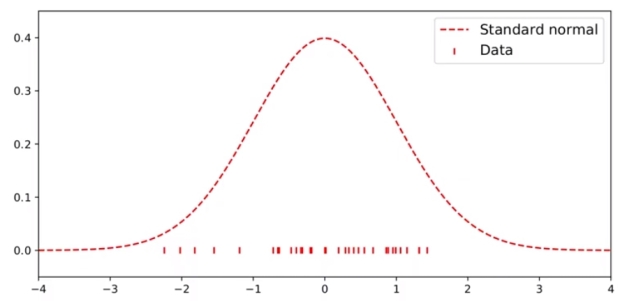
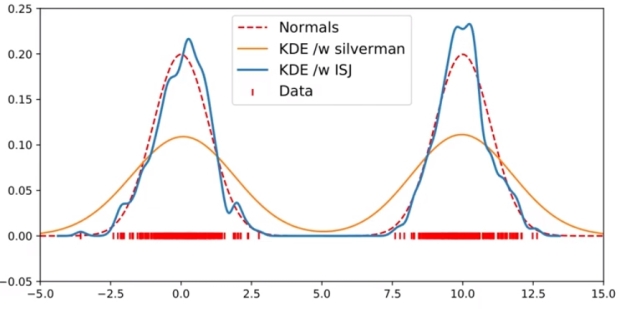
아래와 같은 Standard normal 그래프가 있을 때에, silverman 이라는 smooth 한 그래프를 적용하면 (bandwidth 가 큼) 데이터를 잘 반영하게 된다.
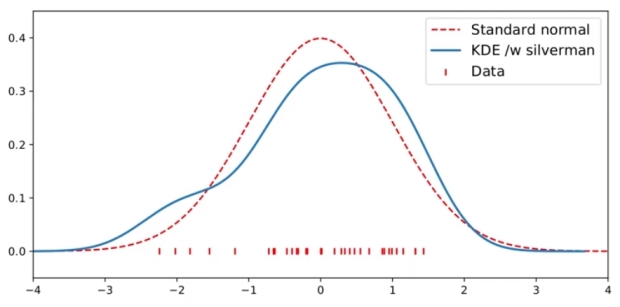
하지만 아래와 같이 데이터의 분포가 큰 경우에는 bandwidth 가 큰 silverman 보다는 bandwidth 가 작은 ISJ 를 적용하는 것이 데이터의 밀도를 더 잘 나타낼 수 있다.
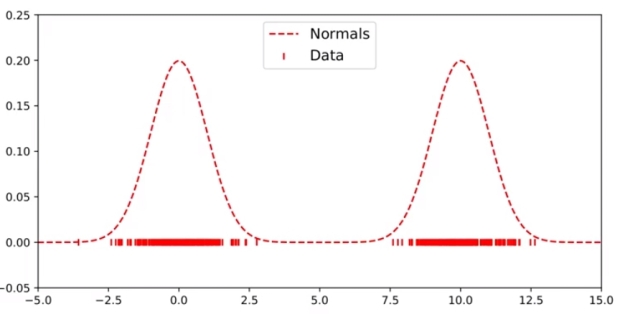
[WEIGHT 에 따른 KDE]
지금까지는 모든 data의 가중치 weight 가 같은 예제였다면, 데이터마다 가중치 (weight) 가 다를 때에, KDE 를 살펴보자. 아래 그림과 같이 data 의 크기에 따라 weight 가 다르고 모두 h개 일 때에 아래와 같이 나타낼 수 있다.

데이터의 weight 에 따라 kernel 을 그리면 아래 그래프와 같으며, KDE 를 그리면 데이터의 weight 를 반영한 KDE 가 생성된다.

[BOUNDED DOMAINS]
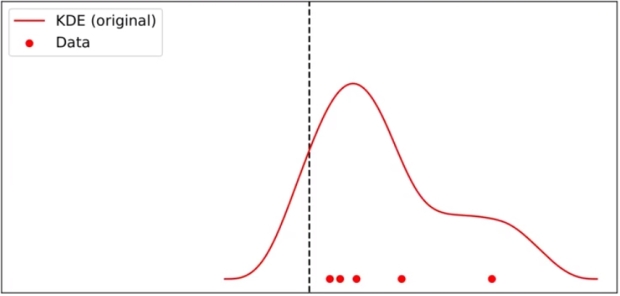
아래과 같이 boundary 가 있는 경우에, 위에서 그린 그대로 KDE 를 그리면 boundary 를 반영하지 못한 그래프가 생성된다.
점선 부분을 boundary 하고 하면, boundary 밖에도 데이터가 있는 것처럼 인식하고 KDE를 생성하기 때문에 boundary 근처에 위치한 데이터의 밀도를 정확하게 나타낼 수 없다.

이런 경우, mirror 방법을 이용하면 boundary data 밀도를 반영할 수 있다.
우선, boundary 를 기준으로 대칭된 데이터(Mirrored data)를 만들고 대칭된 데이터의 KDE를 생성한다.
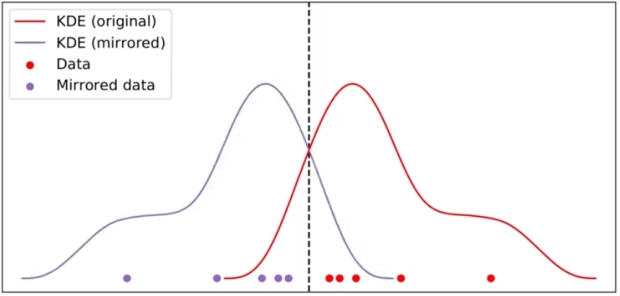
그리고 mirrored KDE와 기존 KDE 를 합친 KDE 를 생성한 후, boundary 를 따라 밖의 부분을 제거한다.
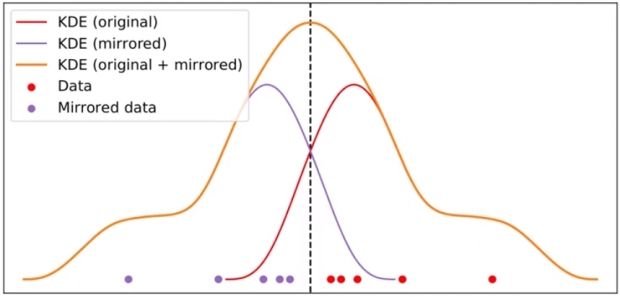

위의 파란색 그래프는 boundary 를 반영한 final KDE 이다. boundary 를 반영하지 않고 그린 KDE와 다르게 boundary 부분에 밀집한 데이터의 밀도를 표현한 것을 확인할 수 있다.
도움될 만한 자료들
http://jakevdp.github.io/blog/2013/12/01/kernel-density-estimation/
https://github.com/tommyod/KDEpy
참고: https://www.youtube.com/watch?v=x5zLaWT5KPs
